

뼈 연령 판독 AI기술 개발한 업체 “SW인력 확보가 더 어려워”
김재희기자
입력 2017-03-16 03:00 수정 2017-04-10 14:28
기사공유 |
[4차 산업혁명의 길을 묻다]<1> 한국 4차 산업혁명 현주소 ― AI 플랫폼 기업들의 고충
“오바마 아내의 이름은 뭐야?” 헤드마운티드디스플레이(HMD)를 착용하자 인공지능(AI) 플랫폼 ‘아담(ADAMs)’의 두뇌가 가상현실(VR)로 눈앞에 펼쳐진다. ‘오바마’와 관련된 모든 정보가 아담의 두뇌에서 마인드맵처럼 가지를 쳐나간다. 그중 ‘미셸 오바마’의 사진이 기자의 눈앞으로 확대돼 나타난다. 2초가 채 되지 않아 아담이 말한다. “오바마 부인의 이름은 미셸 오바마입니다.”
서울 강남구에 위치한 AI 플랫폼 기업 솔트룩스는 사무실에 마련된 시연 공간에서 아담이 사람의 질문을 자연어 처리 기술을 통해 이해하는 과정과 저장된 데이터를 활용해 답변을 찾아가는 과정을 시각화해 VR로 선보였다.
○ AI 원천기술 보유 기업, 뷰노코리아와 솔트룩스
 IBM 왓슨보다 한국어에 강한 AI 9일 서울 강남구에 위치한 인공지능(AI) 플랫폼 기업
‘솔트룩스’ 사무실에서 솔트룩스 관계자가 자체 개발한 AI 플랫폼 ‘아담(ADAMs)’을 시연하고 있다. 아담은 솔트룩스가
17년간 개발해 온 자연어 처리, 기계학습 등 기술을 탑재해 자체 개발한 AI 플랫폼이다. 안철민 기자 acm08@donga.com
IBM 왓슨보다 한국어에 강한 AI 9일 서울 강남구에 위치한 인공지능(AI) 플랫폼 기업
‘솔트룩스’ 사무실에서 솔트룩스 관계자가 자체 개발한 AI 플랫폼 ‘아담(ADAMs)’을 시연하고 있다. 아담은 솔트룩스가
17년간 개발해 온 자연어 처리, 기계학습 등 기술을 탑재해 자체 개발한 AI 플랫폼이다. 안철민 기자 acm08@donga.com
2000년 설립된 후 자연어 처리 기술 개발에 집중해 온 솔트룩스는 IBM, 구글 등과 경쟁할 수 있는 AI 원천기술 보유 기업 중 하나다. 솔트룩스는 얼마 전 자체 개발한 AI 플랫폼 아담을 공개했다. 아담에는 솔트룩스가 17년간 개발해 온 자연어 처리와 기계학습 등의 AI 기술이 적용됐다. 솔트룩스 사무실에서 만난 이경일 대표이사(CEO)는 IBM의 AI 플랫폼 ‘왓슨’과 비교해 아담은 한국어 자연어 처리에서 더 강하다고 설명했다. 이 대표는 “올해 1월 국내 금융회사와의 서비스 계약에서 왓슨과 아담이 경쟁을 했는데 IBM은 시연을 하지 못했지만 아담은 한국어 자연어 처리 기술, 방대한 한국어 데이터 등을 기반으로 시연했다”고 말했다.
2014년 설립된 뷰노코리아는 자체 개발한 딥러닝(인공신경망을 기반으로 기계가 스스로 학습하는 기술) 엔진을 활용해 폐질환, 골 연령 등 진단을 돕는 의료영상 분석 시스템을 개발한다. 직원 수는 16명에 불과하지만 기술력만은 글로벌 기업에 뒤지지 않는다. 최근 개발한 골 연령 판독 프로그램 ‘본에이지’는 5분이었던 골 연령 판독 시간을 20초로 줄였다. 정확도는 96%에 이른다.
정규환 뷰노코리아 최고기술경영자(CTO·이사)는 서울 강남구의 뷰노코리아 사무실에서 기자와 만나 “한국은 의료 분야의 정보기술(IT) 시스템이 잘 갖춰져 있기 때문에 의료영상 등 데이터가 많다. 고품질 데이터를 대량으로 확보해 분석할 수 있다”고 말했다.
○ ‘저품질 데이터+정부 규제+인재난’ 삼중고
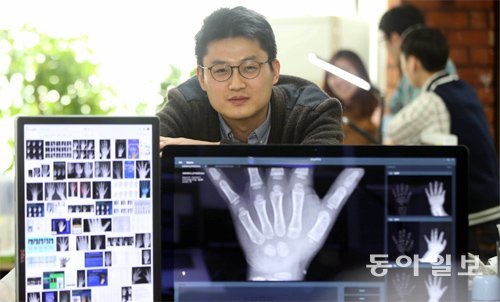 뼈 연령 판독 정확도 96% 10일 서울 강남구의 딥 러닝 엔진 기반 의료영상 분석 스타트업
‘뷰노코리아’ 사무실에서 정규환 최고기술경영자(CTO)가 최근 개발한 뼈 연령 판독 프로그램 ‘본에이지’를 소개하고 있다. 박영대 기자 sannae@donga.com
뼈 연령 판독 정확도 96% 10일 서울 강남구의 딥 러닝 엔진 기반 의료영상 분석 스타트업
‘뷰노코리아’ 사무실에서 정규환 최고기술경영자(CTO)가 최근 개발한 뼈 연령 판독 프로그램 ‘본에이지’를 소개하고 있다. 박영대 기자 sannae@donga.com
정부가 2013년부터 ‘정부 3.0’이라는 기치 아래 공공기관의 데이터를 민간에 개방하고 있지만 정작 현장에서의 활용도는 떨어진다는 목소리가 나온다. 2, 3차 가공을 거친 양질의 데이터가 아니기 때문에 기업이 활용하기 어렵다는 것이다.
정 이사는 국내 환자들의 처방전 데이터를 보유하고 있는 건강보험심사평가원의 데이터에 대해 “심평원 데이터는 의료수가 문제로 청구된 진단명과 실제 최종 진단명이 다른 경우가 있고, 환자의 과거 병력이나 가족력 검사 결과 정보 등 상세정보가 부족해 환자별 맞춤 서비스를 제공하기에는 한계가 있다”고 지적했다. 그는 “현재로서는 개별 병원과의 파트너십을 통한 데이터 수집이 유일한 방법이다”라고 말했다.
개별 파트너십을 통해 수집한 데이터 역시 활용이 녹록지 않다. 데이터의 형식과 내용이 표준화되지 않은 채 개방되기 때문이다. 정 이사는 “각 병원에서 수집한 데이터들의 형식과 내용이 달라 이를 별도로 통합하는 과정이 필요하다”고 말했다.
소프트웨어(SW) 분야 인재 부족도 심각하다. 서울대 컴퓨터공학부의 정원은 1999년 90명에서 지난해 55명으로 절반 가까이 줄었다. 이 대표는 “중국과 인도는 AI SW 개발 인력이 7, 8년 사이 두 배로 늘었지만 한국은 그대로다”라고 말했다. 정 이사는 “박사급 고급 인력은 거액의 연봉을 제시하는 대기업에서 다 데려가기 때문에 자금이 부족한 스타트업은 고급 SW 인력을 스카우트하기가 하늘의 별 따기다”라고 말했다.
○ 돌파구는 선택과 집중
전문가들이 찾은 돌파구는 ‘선택과 집중’이다. 글로벌 기업은 영상 인식 및 합성, 음성 인식 및 합성 등 인공지능 기술 전반에 발을 담그고 있지만 자본과 인력이 부족한 한국은 특정 분야에 집중해야 한다는 것이다. 트레이시 차이 가트너 총괄부사장은 13일 서울 강남구 트레이드타워에서 기자와 만나 “스타트업은 범용 AI 플랫폼을 만들기보다 특정 영역에 집중해야 한다. 특히 축적된 데이터가 많고 디지털화한 금융 분야가 가장 유망하다”고 제언했다.
명함 서비스 스타트업 ‘리멤버’는 틈새시장을 개척한 사례다. 리멤버는 이용자가 명함을 사진으로 찍으면 이름, 전화번호, 주소 등을 정리해 자동으로 등록해주는 기업이다. 리멤버에는 각 이용자가 등록한 명함 데이터가 쌓이기 때문에 이를 기반으로 어떤 직군끼리 관계를 맺는지 대한민국의 비즈니스 관계망을 그릴 수도 있는 것이다.
정부가 나서서 데이터 표준화 작업을 빨리 이뤄내야 한다는 지적도 나왔다. 솔트룩스는 데이터의 형식 및 내용 표준화 기술을 갖추고 있기 때문에 자체적으로 데이터를 가공해 활용할 수 있다. 해당 기술이 없는 기업은 별도의 비용을 들여 데이터를 가공하거나 아예 활용하지 못하기도 한다.
이 대표는 “데이터 표준화 작업을 회사 또는 기관에서 각자 수행하는 것은 큰 사회적 비용이다. 개방된 데이터를 정부나 한 기관이 컨트롤타워가 돼 진행하는 것이 훨씬 효율적이다. 한국정보화진흥원에서 해당 작업을 빠르게 진행할 필요가 있다”고 지적했다.
김재희 기자 jetti@donga.com
“오바마 아내의 이름은 뭐야?” 헤드마운티드디스플레이(HMD)를 착용하자 인공지능(AI) 플랫폼 ‘아담(ADAMs)’의 두뇌가 가상현실(VR)로 눈앞에 펼쳐진다. ‘오바마’와 관련된 모든 정보가 아담의 두뇌에서 마인드맵처럼 가지를 쳐나간다. 그중 ‘미셸 오바마’의 사진이 기자의 눈앞으로 확대돼 나타난다. 2초가 채 되지 않아 아담이 말한다. “오바마 부인의 이름은 미셸 오바마입니다.”
서울 강남구에 위치한 AI 플랫폼 기업 솔트룩스는 사무실에 마련된 시연 공간에서 아담이 사람의 질문을 자연어 처리 기술을 통해 이해하는 과정과 저장된 데이터를 활용해 답변을 찾아가는 과정을 시각화해 VR로 선보였다.
○ AI 원천기술 보유 기업, 뷰노코리아와 솔트룩스
IBM 왓슨보다 한국어에 강한 AI 9일 서울 강남구에 위치한 인공지능(AI) 플랫폼 기업
‘솔트룩스’ 사무실에서 솔트룩스 관계자가 자체 개발한 AI 플랫폼 ‘아담(ADAMs)’을 시연하고 있다. 아담은 솔트룩스가
17년간 개발해 온 자연어 처리, 기계학습 등 기술을 탑재해 자체 개발한 AI 플랫폼이다. 안철민 기자 acm08@donga.com2000년 설립된 후 자연어 처리 기술 개발에 집중해 온 솔트룩스는 IBM, 구글 등과 경쟁할 수 있는 AI 원천기술 보유 기업 중 하나다. 솔트룩스는 얼마 전 자체 개발한 AI 플랫폼 아담을 공개했다. 아담에는 솔트룩스가 17년간 개발해 온 자연어 처리와 기계학습 등의 AI 기술이 적용됐다. 솔트룩스 사무실에서 만난 이경일 대표이사(CEO)는 IBM의 AI 플랫폼 ‘왓슨’과 비교해 아담은 한국어 자연어 처리에서 더 강하다고 설명했다. 이 대표는 “올해 1월 국내 금융회사와의 서비스 계약에서 왓슨과 아담이 경쟁을 했는데 IBM은 시연을 하지 못했지만 아담은 한국어 자연어 처리 기술, 방대한 한국어 데이터 등을 기반으로 시연했다”고 말했다.
2014년 설립된 뷰노코리아는 자체 개발한 딥러닝(인공신경망을 기반으로 기계가 스스로 학습하는 기술) 엔진을 활용해 폐질환, 골 연령 등 진단을 돕는 의료영상 분석 시스템을 개발한다. 직원 수는 16명에 불과하지만 기술력만은 글로벌 기업에 뒤지지 않는다. 최근 개발한 골 연령 판독 프로그램 ‘본에이지’는 5분이었던 골 연령 판독 시간을 20초로 줄였다. 정확도는 96%에 이른다.
정규환 뷰노코리아 최고기술경영자(CTO·이사)는 서울 강남구의 뷰노코리아 사무실에서 기자와 만나 “한국은 의료 분야의 정보기술(IT) 시스템이 잘 갖춰져 있기 때문에 의료영상 등 데이터가 많다. 고품질 데이터를 대량으로 확보해 분석할 수 있다”고 말했다.
○ ‘저품질 데이터+정부 규제+인재난’ 삼중고
뼈 연령 판독 정확도 96% 10일 서울 강남구의 딥 러닝 엔진 기반 의료영상 분석 스타트업
‘뷰노코리아’ 사무실에서 정규환 최고기술경영자(CTO)가 최근 개발한 뼈 연령 판독 프로그램 ‘본에이지’를 소개하고 있다. 박영대 기자 sannae@donga.com정부가 2013년부터 ‘정부 3.0’이라는 기치 아래 공공기관의 데이터를 민간에 개방하고 있지만 정작 현장에서의 활용도는 떨어진다는 목소리가 나온다. 2, 3차 가공을 거친 양질의 데이터가 아니기 때문에 기업이 활용하기 어렵다는 것이다.
정 이사는 국내 환자들의 처방전 데이터를 보유하고 있는 건강보험심사평가원의 데이터에 대해 “심평원 데이터는 의료수가 문제로 청구된 진단명과 실제 최종 진단명이 다른 경우가 있고, 환자의 과거 병력이나 가족력 검사 결과 정보 등 상세정보가 부족해 환자별 맞춤 서비스를 제공하기에는 한계가 있다”고 지적했다. 그는 “현재로서는 개별 병원과의 파트너십을 통한 데이터 수집이 유일한 방법이다”라고 말했다.
개별 파트너십을 통해 수집한 데이터 역시 활용이 녹록지 않다. 데이터의 형식과 내용이 표준화되지 않은 채 개방되기 때문이다. 정 이사는 “각 병원에서 수집한 데이터들의 형식과 내용이 달라 이를 별도로 통합하는 과정이 필요하다”고 말했다.
소프트웨어(SW) 분야 인재 부족도 심각하다. 서울대 컴퓨터공학부의 정원은 1999년 90명에서 지난해 55명으로 절반 가까이 줄었다. 이 대표는 “중국과 인도는 AI SW 개발 인력이 7, 8년 사이 두 배로 늘었지만 한국은 그대로다”라고 말했다. 정 이사는 “박사급 고급 인력은 거액의 연봉을 제시하는 대기업에서 다 데려가기 때문에 자금이 부족한 스타트업은 고급 SW 인력을 스카우트하기가 하늘의 별 따기다”라고 말했다.
○ 돌파구는 선택과 집중
전문가들이 찾은 돌파구는 ‘선택과 집중’이다. 글로벌 기업은 영상 인식 및 합성, 음성 인식 및 합성 등 인공지능 기술 전반에 발을 담그고 있지만 자본과 인력이 부족한 한국은 특정 분야에 집중해야 한다는 것이다. 트레이시 차이 가트너 총괄부사장은 13일 서울 강남구 트레이드타워에서 기자와 만나 “스타트업은 범용 AI 플랫폼을 만들기보다 특정 영역에 집중해야 한다. 특히 축적된 데이터가 많고 디지털화한 금융 분야가 가장 유망하다”고 제언했다.
명함 서비스 스타트업 ‘리멤버’는 틈새시장을 개척한 사례다. 리멤버는 이용자가 명함을 사진으로 찍으면 이름, 전화번호, 주소 등을 정리해 자동으로 등록해주는 기업이다. 리멤버에는 각 이용자가 등록한 명함 데이터가 쌓이기 때문에 이를 기반으로 어떤 직군끼리 관계를 맺는지 대한민국의 비즈니스 관계망을 그릴 수도 있는 것이다.
정부가 나서서 데이터 표준화 작업을 빨리 이뤄내야 한다는 지적도 나왔다. 솔트룩스는 데이터의 형식 및 내용 표준화 기술을 갖추고 있기 때문에 자체적으로 데이터를 가공해 활용할 수 있다. 해당 기술이 없는 기업은 별도의 비용을 들여 데이터를 가공하거나 아예 활용하지 못하기도 한다.
이 대표는 “데이터 표준화 작업을 회사 또는 기관에서 각자 수행하는 것은 큰 사회적 비용이다. 개방된 데이터를 정부나 한 기관이 컨트롤타워가 돼 진행하는 것이 훨씬 효율적이다. 한국정보화진흥원에서 해당 작업을 빠르게 진행할 필요가 있다”고 지적했다.
김재희 기자 jetti@donga.com

비즈N 탑기사












![[시승기] 제주에서 느끼는 드라이빙의 즐거움…‘포르쉐 올레 드라이브’](https://dimg.donga.com/wps/ECONOMY/FEED/BIZN_FEED_EVLOUNGE/132703912.2.thumb.jpg "[시승기] 제주에서 느끼는 드라이빙의 즐거움…‘포르쉐 올레 드라이브’")
 ‘책 출간’ 한동훈, 정계 복귀 움직임에 테마株 강세
‘책 출간’ 한동훈, 정계 복귀 움직임에 테마株 강세 조선 후기 화가 신명연 ‘화훼도 병풍’ 기념우표 발행
조선 후기 화가 신명연 ‘화훼도 병풍’ 기념우표 발행 붕괴 교량과 동일·유사 공법 3곳 공사 전면 중지
붕괴 교량과 동일·유사 공법 3곳 공사 전면 중지 명동 ‘위조 명품’ 판매 일당 덜미…SNS로 관광객 속였다
명동 ‘위조 명품’ 판매 일당 덜미…SNS로 관광객 속였다 “나대는 것 같아 안올렸는데”…기안84 ‘100 챌린지’ 뭐길래
“나대는 것 같아 안올렸는데”…기안84 ‘100 챌린지’ 뭐길래- ‘전참시’ 이연희, 득녀 5개월만 복귀 일상…아침 산책+운동 루틴
- 국내 기술로 개발한 ‘한국형 잠수함’ 기념우표 발행
- ‘아파트 지하주차장서 음주운전’ 인천시의원 송치
- 학령인구 감소 탓에 도심지 초교마저 학급 편성 ‘비상’
- 상속인 행세하며 100억 원 갈취한 사기꾼 일당 붙잡혀
 “과자에 반도체 입혔더니”…‘SK하이닉스 과자’ 20만개 팔렸다
“과자에 반도체 입혔더니”…‘SK하이닉스 과자’ 20만개 팔렸다 오늘부터 휴대폰 개통에 ‘안면인증’ 시범도입…“대포폰 차단”
오늘부터 휴대폰 개통에 ‘안면인증’ 시범도입…“대포폰 차단” 수출 사상 첫 7000억 달러 눈앞… 반도체 고군분투
수출 사상 첫 7000억 달러 눈앞… 반도체 고군분투 서울 서북권 관문 상암·수색의 변화…‘직주락 미래도시’ 변신
서울 서북권 관문 상암·수색의 변화…‘직주락 미래도시’ 변신 삼성전자-SK “미국산 AI 수출 프로그램 동참할 것”
삼성전자-SK “미국산 AI 수출 프로그램 동참할 것”- 국세청, 쿠팡 美본사 거래내역도 뒤진다… 전방위 세무조사
- 다이어트 콜라의 역습?…“아스파탐, 심장·뇌 손상 위험” 경고
- 12월 1~20일 수출 430억달러 6.8% 증가…반도체 41.8%↑
- 23일부터 폰 개통에 안면인증…내년 3월부터 정식 도입
- 서울 아파트 월세, 올 3% 넘게 올라… 송파-용산은 6% 훌쩍