

빅데이터 산업의 연료, 가명정보와 익명정보란?
동아닷컴
입력 2018-10-08 16:43 수정 2018-10-08 16:47
기사공유 |
4차산업혁명의 주요 기술 중 하나로 꼽히는 빅데이터 및 인공지능 연구에 있어서 데이터를 처리하는 데 필요한 컴퓨팅 성능이나 효율적 처리를 위한 알고리즘은 중요한 요소다. 하지만, 무엇보다 인공지능을 학습시키기 위한 데이터 그 자체의 중요성도 빼놓을 수는 없다. 더 다양하고 방대한 데이터로 학습한 인공지능은 기존에는 예상하지 못했던 가능성과 변수 등을 찾아낼 수 있다.
이러한 가능성 때문에 최근 데이터 경제 활성화에 관한 산업계의 요구가 커졌으며, 정부 역시 데이터와 관련한 규제를 완화해 데이터 강국으로 나아가자는 뜻을 밝혔다. 물론 이해상충은 있다. 산업계에서는 개인정보보호와 관련한 규제를 완화해 발전 가능성을 열어 달라고 요구하지만, 시민단체 등에서는 개인정보 보호에 관한 요구가 커지고 있는 상황이다.
 개인정보보호와 데이터 산업 발전은 상충관계에 있다(출처=IT동아)
개인정보보호와 데이터 산업 발전은 상충관계에 있다(출처=IT동아)
인공지능이 학습하기 위해 사용하는 데이터 중에는 우리의 민감한 개인정보가 포함될 가능성이 있기 때문이다. 따라서 데이터를 활용함에 있어서 민감한 개인정보를 제거해 개인정보를 보호하는 비식별 조치의 필요성도 크다.
빅데이터를 위해 수집/활용하는 종류는 크게 가명정보를 포함한 개인정보, 익명정보, 개인정보와 관련 없는 데이터 등 세 가지로 나눌 수 있다. 우선 개인정보란 이름, 성별, 나이, 전화번호, 이메일 주소, 거주지 등 누군가를 식별할 수 있는 식별자와 준식별자가 포함된 정보를 말한다. 여기서 누군가를 특정할 수 있는 이름, 전화번호, 이메일 등의 정보를 식별자라고 부르며, 개인정보에서 식별자를 다른 표현으로 바꾸거나 가린 것을 가명정보라고 한다. 예를 들어, IT동아, 이상우, 32세, 남성, 070-8255-8208, 서울시 마포구 서교동 395-95, lswoo@itdonga.com 등의 개인정보가 있을 때, 이 정보를 IT동아, 이XX, 30대, 남성, 070-XXXX-XXXX, XXXXX@itdonga.com 등으로 바꾼 것을 가명정보라고 부를 수 있다.
익명정보는 여기서 한층 더 나아가 식별자를 완전히 삭제하고, 나이나 성별 혹은 주소 등 준식별자에 해당하는 정보를 범주화해 누구인지 정확하게 특정할 수 없도록 처리하는 것을 말한다. 예를 들어 이름은 완전히 삭제하고, 주소는 서울시 마포구 등으로 범주화 하는 식이다.
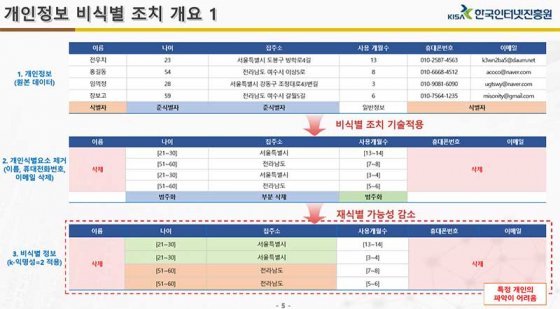 개인정보 비식별 조치(출처=IT동아)
개인정보 비식별 조치(출처=IT동아)
앞서 언급한 것처럼 빅데이터 산업 활성화와 데이터를 활용한 경제적 가치를 만들기 위해서는 개인정보를 포함한 모든 데이터를 적극적으로 활용하는 것이 유리하다. 한편으로는 개인정보 보호와 관련한 이슈 역시 빼놓을 수 없기 때문에 개인정보를 가명/익명정보로 만드는 비식별 조치의 중요성도 크다.
특히 개인정보에 관한 비식별 조치에 있어서 관건은 데이터로서의 활용 가치를 충분히 남기면서, 이 정보를 통해 특정 개인을 식별하기 어려운 수준으로 가공해야 하는 점이다. 정보를 지나치게 많이 남길 경우 개인정보보호와 관련한 문제가 생길 수 있으며, 반대로 많이 제거할 경우 활용 가치가 떨어지기 때문이다.
정부는 최근 규제개혁을 통해 기업이 이름, 주민등록번호 등의 식별자를 제거한 가명정보를 더 편하게 활용하고, 빅데이터 기반의 산업 활성화를 지원하겠다는 의지를 밝혔다. 실제로 이미 EU는 GDPR을 통해 개인정보 활용에 대한 근거와 함께 정보주체의 권리를 보장하는 방안을 마련했으며, 미국이나 일본 역시 빅데이터 처리 목적의 비식별 정보를 활용하는 근거나 가이드라인을 제공 중이다.
국내 역시 단순한 규제 완화로 그쳐서는 안되며, 개인정보 보호에 관한 기업의 책임을 강화해야 한다. 예를 들어 GDPR의 경우 개인정보 처리에 대한 적법성을 강조하며, 정보주체의 명시적 동의 없이는 이를 활용할 수 없다. 국내 역시 비식별 조치 된 개인정보를 고의로 재식별(다시 원래 개인정보로 복구하는 일)할 경우 형사 처벌에 대한 가능성을 개인정보보호법 개정안에 추가하는 등 정보 활용에 대한 정보주체의 권리를 확보하는 방안을 마련해야 한다.
최근 주목받고 있는 블록체인을 적용하는 것도 좋은 방법이다. 블록체인의 경우 정보주체가 자신의 개인정보중에서 어떤 내용이 어디서 어떻게 쓰였는지 쉽게 추적 가능하며, 위변조의 가능성 역시 적기 때문이다.
개인정보를 보호하면서 데이터로서의 가치를 남기는 비식별 처리 방식 역시 개발해야 한다. 개인정보보호와 관련해 국내 대표 기관인 한국인터넷진흥원은 이를 위해 최근 데이터 경제 활성화 지원 확대를 목적으로 비식별 조치 기술 개발 및 지원 업무 확대, 비식별 조치 경진대회를 통한 사례 발굴 등을 시도하고 있다.
특히 완전한 개인정보보다 비식별 처리한 가명/익명정보를 활용하는 것이 데이터 과학 발전 측면에서 더 많은 도움이 된다. 비식별 조치를 한 데이터를 통해 (신원을 알 수는 없지만) 특정 인물의 취향이나 성향을 분석하고, 최적화한 상품이나 콘텐츠를 제공하는 인공지능 알고리즘 개발이 가능하다. 이러한 알고리즘은 단순히 개인정보를 이용하는 것보다 상대적으로 개발이 어렵지만, 장기적으로는 사용자 동의 없이 활용할 수 있는 정만으로도 개인 맞춤형 인공지능 서비스를 제공할 수 있게 된다.
데이터 산업 발전 측면에 있어서 이번 정부의 규제 완화 전망은 바람직하다. 활용할 수 있는 데이터가 많아지면 그만큼 다양한 형태의 빅데이터 기반 사업과 연구개발이 가능하기 때문이다. 실제로 현재 인공지능과 관련해 이름을 떨치고 있는 구글, 마이크로소프트 등의 기업은 전세계에 있는 수억 명의 가입자를 통해 데이터를 확보하고 이를 연구에 활용하고 있는 만큼, 국내 역시 지나친 규제를 완화해 역량을 키워야 한다. 하지만 이 과정에서 정보주체의 권리를 잊어서는 안된다. 사용자는 자신의 정보를 누가, 어디서, 어떻게 사용하는지 투명하게 확인할 수 있어야 하며, 기업은 목적 달성 시 지체없이 이러한 정보를 파기해야 할 것이다.
동아닷컴 IT전문 이상우 기자 lswoo@donga.com
이러한 가능성 때문에 최근 데이터 경제 활성화에 관한 산업계의 요구가 커졌으며, 정부 역시 데이터와 관련한 규제를 완화해 데이터 강국으로 나아가자는 뜻을 밝혔다. 물론 이해상충은 있다. 산업계에서는 개인정보보호와 관련한 규제를 완화해 발전 가능성을 열어 달라고 요구하지만, 시민단체 등에서는 개인정보 보호에 관한 요구가 커지고 있는 상황이다.
개인정보보호와 데이터 산업 발전은 상충관계에 있다(출처=IT동아)인공지능이 학습하기 위해 사용하는 데이터 중에는 우리의 민감한 개인정보가 포함될 가능성이 있기 때문이다. 따라서 데이터를 활용함에 있어서 민감한 개인정보를 제거해 개인정보를 보호하는 비식별 조치의 필요성도 크다.
빅데이터를 위해 수집/활용하는 종류는 크게 가명정보를 포함한 개인정보, 익명정보, 개인정보와 관련 없는 데이터 등 세 가지로 나눌 수 있다. 우선 개인정보란 이름, 성별, 나이, 전화번호, 이메일 주소, 거주지 등 누군가를 식별할 수 있는 식별자와 준식별자가 포함된 정보를 말한다. 여기서 누군가를 특정할 수 있는 이름, 전화번호, 이메일 등의 정보를 식별자라고 부르며, 개인정보에서 식별자를 다른 표현으로 바꾸거나 가린 것을 가명정보라고 한다. 예를 들어, IT동아, 이상우, 32세, 남성, 070-8255-8208, 서울시 마포구 서교동 395-95, lswoo@itdonga.com 등의 개인정보가 있을 때, 이 정보를 IT동아, 이XX, 30대, 남성, 070-XXXX-XXXX, XXXXX@itdonga.com 등으로 바꾼 것을 가명정보라고 부를 수 있다.
익명정보는 여기서 한층 더 나아가 식별자를 완전히 삭제하고, 나이나 성별 혹은 주소 등 준식별자에 해당하는 정보를 범주화해 누구인지 정확하게 특정할 수 없도록 처리하는 것을 말한다. 예를 들어 이름은 완전히 삭제하고, 주소는 서울시 마포구 등으로 범주화 하는 식이다.
개인정보 비식별 조치(출처=IT동아)앞서 언급한 것처럼 빅데이터 산업 활성화와 데이터를 활용한 경제적 가치를 만들기 위해서는 개인정보를 포함한 모든 데이터를 적극적으로 활용하는 것이 유리하다. 한편으로는 개인정보 보호와 관련한 이슈 역시 빼놓을 수 없기 때문에 개인정보를 가명/익명정보로 만드는 비식별 조치의 중요성도 크다.
특히 개인정보에 관한 비식별 조치에 있어서 관건은 데이터로서의 활용 가치를 충분히 남기면서, 이 정보를 통해 특정 개인을 식별하기 어려운 수준으로 가공해야 하는 점이다. 정보를 지나치게 많이 남길 경우 개인정보보호와 관련한 문제가 생길 수 있으며, 반대로 많이 제거할 경우 활용 가치가 떨어지기 때문이다.
정부는 최근 규제개혁을 통해 기업이 이름, 주민등록번호 등의 식별자를 제거한 가명정보를 더 편하게 활용하고, 빅데이터 기반의 산업 활성화를 지원하겠다는 의지를 밝혔다. 실제로 이미 EU는 GDPR을 통해 개인정보 활용에 대한 근거와 함께 정보주체의 권리를 보장하는 방안을 마련했으며, 미국이나 일본 역시 빅데이터 처리 목적의 비식별 정보를 활용하는 근거나 가이드라인을 제공 중이다.
국내 역시 단순한 규제 완화로 그쳐서는 안되며, 개인정보 보호에 관한 기업의 책임을 강화해야 한다. 예를 들어 GDPR의 경우 개인정보 처리에 대한 적법성을 강조하며, 정보주체의 명시적 동의 없이는 이를 활용할 수 없다. 국내 역시 비식별 조치 된 개인정보를 고의로 재식별(다시 원래 개인정보로 복구하는 일)할 경우 형사 처벌에 대한 가능성을 개인정보보호법 개정안에 추가하는 등 정보 활용에 대한 정보주체의 권리를 확보하는 방안을 마련해야 한다.
최근 주목받고 있는 블록체인을 적용하는 것도 좋은 방법이다. 블록체인의 경우 정보주체가 자신의 개인정보중에서 어떤 내용이 어디서 어떻게 쓰였는지 쉽게 추적 가능하며, 위변조의 가능성 역시 적기 때문이다.
개인정보를 보호하면서 데이터로서의 가치를 남기는 비식별 처리 방식 역시 개발해야 한다. 개인정보보호와 관련해 국내 대표 기관인 한국인터넷진흥원은 이를 위해 최근 데이터 경제 활성화 지원 확대를 목적으로 비식별 조치 기술 개발 및 지원 업무 확대, 비식별 조치 경진대회를 통한 사례 발굴 등을 시도하고 있다.
특히 완전한 개인정보보다 비식별 처리한 가명/익명정보를 활용하는 것이 데이터 과학 발전 측면에서 더 많은 도움이 된다. 비식별 조치를 한 데이터를 통해 (신원을 알 수는 없지만) 특정 인물의 취향이나 성향을 분석하고, 최적화한 상품이나 콘텐츠를 제공하는 인공지능 알고리즘 개발이 가능하다. 이러한 알고리즘은 단순히 개인정보를 이용하는 것보다 상대적으로 개발이 어렵지만, 장기적으로는 사용자 동의 없이 활용할 수 있는 정만으로도 개인 맞춤형 인공지능 서비스를 제공할 수 있게 된다.
데이터 산업 발전 측면에 있어서 이번 정부의 규제 완화 전망은 바람직하다. 활용할 수 있는 데이터가 많아지면 그만큼 다양한 형태의 빅데이터 기반 사업과 연구개발이 가능하기 때문이다. 실제로 현재 인공지능과 관련해 이름을 떨치고 있는 구글, 마이크로소프트 등의 기업은 전세계에 있는 수억 명의 가입자를 통해 데이터를 확보하고 이를 연구에 활용하고 있는 만큼, 국내 역시 지나친 규제를 완화해 역량을 키워야 한다. 하지만 이 과정에서 정보주체의 권리를 잊어서는 안된다. 사용자는 자신의 정보를 누가, 어디서, 어떻게 사용하는지 투명하게 확인할 수 있어야 하며, 기업은 목적 달성 시 지체없이 이러한 정보를 파기해야 할 것이다.
동아닷컴 IT전문 이상우 기자 lswoo@donga.com





비즈N 탑기사








![[단독]올해 서울 입주아파트 18곳 중 16곳 유해물질 기준치 초과](https://dimg.donga.com/a/102/54/90/1/wps/ECONOMY/FEED/BIZN_REALESTATE/130326015.2.thumb.jpg "[단독]올해 서울 입주아파트 18곳 중 16곳 유해물질 기준치 초과")




 김숙 “내 건물서 거주+월세 수입 생활이 로망”
김숙 “내 건물서 거주+월세 수입 생활이 로망” “20억 받으면서 봉사라고?”…홍명보 감독 발언에 누리꾼 ‘부글’
“20억 받으면서 봉사라고?”…홍명보 감독 발언에 누리꾼 ‘부글’ 세계적 유명 모델이 왜 삼성역·편의점에…“사랑해요 서울” 인증샷
세계적 유명 모델이 왜 삼성역·편의점에…“사랑해요 서울” 인증샷 “사람 치아 나왔다” 5000원짜리 고기 월병 먹던 中여성 ‘경악’
“사람 치아 나왔다” 5000원짜리 고기 월병 먹던 中여성 ‘경악’ “모자로 안가려지네”…박보영, 청순한 미모로 힐링 여행
“모자로 안가려지네”…박보영, 청순한 미모로 힐링 여행- 엄마 편의점 간 사이 ‘탕’…차에 둔 권총 만진 8살 사망
- 8시간 후 자수한 음주 뺑소니 가해자…한문철 “괘씸죄 적용해야”
- 교보생명, 광화문글판 가을편 새단장…윤동주 ‘자화상’
- 힐러리 “내가 못 깬 유리천장, 해리스가 깨뜨릴 것”
- ‘SNS 적극 활동’ 고현정…“너무 자주 올려 지겨우시실까봐 걱정”
 [머니 컨설팅]금리 인하기, 상업용 부동산 투자 주목해야
[머니 컨설팅]금리 인하기, 상업용 부동산 투자 주목해야 금값, 올들어 33% 치솟아… 내년 3000달러 넘을 수도
금값, 올들어 33% 치솟아… 내년 3000달러 넘을 수도 [단독]배달주문 30% 늘때 수수료 3배로 뛰어… “배달영업 포기”
[단독]배달주문 30% 늘때 수수료 3배로 뛰어… “배달영업 포기” 주도주 없는 증시, ‘경영권 분쟁’이 테마주로… 급등락 주의보
주도주 없는 증시, ‘경영권 분쟁’이 테마주로… 급등락 주의보 “두바이 여행한다면 체크”…두바이 피트니스 챌린지
“두바이 여행한다면 체크”…두바이 피트니스 챌린지- 청력 손실, 치매 외 파킨슨병과도 밀접…보청기 착용하면 위험 ‘뚝’
- “오후 5시 영업팀 회의실 예약해줘”…카카오, 사내 AI 비서 ‘버디’ 공개
- “20억 받으면서 봉사라고?”…홍명보 감독 발언에 누리꾼 ‘부글’
- 일상생활 마비 손목 증후군, 당일 수술로 잡는다!
- [고준석의 실전투자]경매 후 소멸하지 않는 후순위 가처분 꼼꼼히 살펴야