

챗GPT란 무엇인가:가장 쉽게 설명해드립니다[서영빈의 데이터경제]
서영빈 기자
입력 2023-02-27 11:00 수정 2023-02-27 11:00
기사공유 |

1904년 독일, 사칙연산을 할 수 있는 천재적인 말 ‘한스’가 나타나 세상을 깜짝 놀라게 한 일이 있었습니다. 당시 수학교사였던 오스텐 씨는 ‘내가 기르는 말은 수학계산도 할 줄 안다’고 자랑하며, 사람들을 모아놓고 자신이 키우던 말이 수학 문제를 맞히는 모습을 보여줬습니다. 수학문제를 내면 문제의 정답만큼 한스가 발굽으로 땅을 두드리는 식이었습니다. “2 곱하기 2는?” 질문을 하면 한스가 발굽으로 땅을 4번 두드리는 것이죠. “하나…둘…셋…” 한스의 발굽과 함께 숫자를 세는 구경꾼들의 목소리는 점점 흥분으로 가득 찼습니다. 한스가 발굽을 네 번 두드리고 멈추자, 충격에 휩싸인 구경꾼들에서 우레와 같은 환호성이 터져 나왔습니다.
수천만 년을 홀로 지성을 가진 생명체로 살아왔던 인간들은, 자신과 흡사한 지적능력을 가진 생물체를 발견하면 엄청난 충격과 기대감, 두려움을 느끼는 것 같습니다. 게다가 그 생물체가 인간이 타고 다니던 ‘말’이라니, 얼마나 놀랍고 무서웠을까요. 자연에 대한 이해도 지금만큼 깊지 않았던 시절, 부랴부랴 동물학자와 심리학자 등 각계 전문가로 이루어진 ‘한스 위원회’를 꾸려 한스를 조사했지만, 위원회는 ‘한스는 지성을 타고났다’며 두 손을 들고 말았습니다. 천재적인 말 한스의 등장은 당시 뉴욕타임즈 1면을 장식했습니다.
한스는 정말 지성을 가진 동물이었을까요? 얼마 가지 않아 한스의 비밀이 밝혀졌습니다. 한스는 수학문제를 풀었던 것이 아니라, 사람들의 반응을 관찰하는 능력이 뛰어났던 거죠. 한스가 발굽을 두드릴 때마다 “하나…둘…셋…넷…”하고 숫자를 세던 군중들의 목소리 톤은 미세하게 변했고, 목소리가 가장 흥분으로 고조됐을 때 발굽을 멈추어야 한다는 걸 한스는 알았던 것입니다. 어쨌든 영리한 말이었던 건 사실이었던 것 같네요. 다만 인간과 유사한 지성을 가진 생물체가 등장했다는 충격은 곧 수그러들었습니다.
100여 년 후 ‘지성을 가진 물체’의 등장에 전 세계는 다시 한번 충격과 공포에 휩싸입니다. 바로 챗GPT입니다. 이번에는 인간과 거의 흡사한, 혹은 더욱 뛰어난 지성체가 나타났다고들 합니다. 물론 챗GPT를 한스의 사례에 비견할 수는 없을 것 같습니다. 이번에는 단순 눈속임이 아니라, 사칙연산은 물론이고 아주 복잡하고 어려운 계산도 척척 수행할 수 있다는 게 틀림없어 보입니다. 인간처럼 시도 쓰고, 질문에 답도 하고, 인간의 지성이 언어를 통해 할 수 있는 거의 모든 일을 할 수 있는 것처럼 보이죠. 어떤 부분에서는 평균적인 인간보다 훨씬 더 뛰어나게 말입니다. 뛰어난 지능을 가진 호모 사피엔스의 등장에 다른 영장류들이 동물원 신세를 지게 됐듯이, 챗GPT의 등장으로 인해 ‘인간이 AI의 애완동물로 살게 되는 게 아니냐’라는 공포스러운 예견도 나옵니다.
두려움을 이겨내는 가장 좋은 방법 중 하나는 ‘분석’입니다. 챗GPT가 어떤 조각들로 구성돼 어떻게 동작하고 있는지, 이해할 수 있는 수준까지 분해해보는 거죠. 그러다보면 챗GPT가 사실 생각보다 그리 무서운 존재가 아니란 걸 알게 될 수도 있죠. 또 챗GPT가 앞으 무엇을 할 수 있을지, 어떤 걸 할 수 없는지도 더 잘 알 수 있지 않을까요.
● 고도로 발달한 ‘다음 낱말 맞추기 기계’
챗GPT는 크게 두 번의 학습을 통해 만들어집니다. 먼저 챗GPT의 본체 격인 ‘GPT’에 지식을 학습시키고, 그 다음엔 GPT에게 질문에 답을 하는 행동을 하도록 학습 시키는 거죠. GPT가 나타내는 ‘Generative Pre-trained Transformer’의 ‘Pre-trained(미리 학습됨)’은 바로 질문에 답하기, 번역하기 등 특정한 행동을 학습시키기 전에 미리 지식만 학습시키는 과정을 거쳤다는 뜻입니다. 이후에 그 GPT에게 ‘챗(chat, 대화)’을 하도록 훈련시켰다는 뜻이죠.
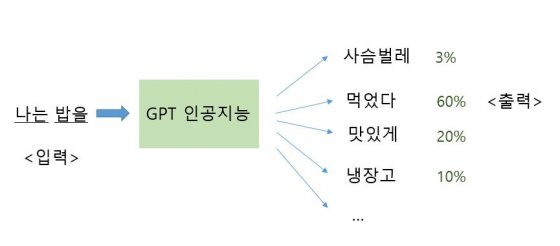
그러면 먼저, GPT는 어떻게 지식을 학습했을까요? ‘다음 낱말 맞추기 연습’을 무한히 반복시킨다고 보면 됩니다. 그 이상도 그 이하도 아니죠. 예를 들어 “나는 밥을 _____”라는 문장이 있을 때, 이 마지막 빈칸에 들어올 단어가 무엇인지 맞추도록 하는 거죠.
GPT 최신 모델인 GPT-3는 약 1억5000개의 단어를 기반으로 만들어졌다고 알려져 있습니다. 그건 GPT가 단어 맞추기 문제를 할 때, ①“나는 밥을 ‘핸드폰’” ②“나는 밥을 ‘사슴벌레’” ③“나는 밥을 ‘버렸다’” ④“나는 밥을 ‘먹었다’”…와 같은 선택지가 1억5000개 있다는 뜻입니다. 5지선다형 문제가 아니라 1억5000지선다형 문제가 되겠네요.
과학자들은 “나는 밥을”로 시작하는 문장 수십 수백만 개를 구해 GPT에게 문제를 내줬습니다. 문제에 대한 답은 늘 같지는 않지만, 특별히 많이 나타나는 답이 있겠죠. 일단 ‘사슴벌레’ 같은 생뚱맞은 명사가 정답이 된 일은 없을 거구요. ‘먹었다’가 가장 자주 정답이 됐겠죠. 혹은 가끔 ‘맛있게’ 같은 단어도 정답이 됐을 것입니다.
그러면 GPT는 이 문제풀이를 통해 ‘밥을’ 다음에는 ‘먹었다’, ‘맛있게’ 와 같은 단어들이 등장할 가능성이 높다는 것을 학습합니다. 이는 달리 말하면, ‘밥’이라는 단어와 ‘먹다’ ‘맛있다’라는 단어 사이에 관련성이 높다는 점을 학습한다는 뜻이죠. 이와 같은 방법으로 ‘밥’이 ‘밥솥’, ‘냉장고’, ‘반찬’ 등과 관련이 있다는 것도 학습하게 될 겁니다.
GPT가 미리 학습했다는 ‘지식’이란 바로 이 단어들 사이의 관계에 지나지 않습니다. ‘지식’이라는 단어는 이보다 더 깊은 의미를 지니겠지만, 적어도 GPT에게는 그 이상의 의미를 지니지 않습니다. GPT는 ‘밥’이 무엇인지, ‘먹었다’가 무엇인지, ‘맛있다’가 무엇인지 전혀 알지 못합니다. 단지 이 단어들끼리 관련성이 높고, 그래서 같은 문장 안에 나타날 가능성이 크다는 것만 알고 있는 것이죠. 이 학습 내용을 바탕으로, 훗날 챗GPT에게 ‘밥과 관련된 이야기를 써줘’라고 부탁하면 ‘맛있는 것을 먹고 싶어서 냉장고를 뒤졌는데 밥과 반찬이 있었다’처럼, 서로 관련 있는 단어들을 집어넣은 그럴듯한 문장을 지어내게 됩니다. 어때요, 어찌 보면 수학문제를 풀 줄 아는 똑똑한 말 한스와 크게 달라 보이지 않습니다.
그 공부방법도 참 무지막지하죠? GPT는 ‘밥’과 ‘밥솥’의 관계를 학습하기 위해 수없이 많은 1억5000지선다형 객관식 문제를 풀었습니다. 위키피디아, 각종 책과 자료들을 비롯한 45테라바이트에 달하는 양의 문서를 문제로 내줬다고 하네요. 학습에 필요한 전기료 등 비용을 충당하는 데 수백만 달러가 들어갔습니다.
그런데 잠깐, ‘나는 밥을’까지만 알려줬더니 ‘맛있다’를 선택할 수 있게 된 기계. 어디서 많이 보지 않았나요? 맞습니다. 이런 종류의 인공지능은 이미 10여 년 전부터 우리의 일상 속에 즐비하게 자리 잡고 있었습니다. 네이버, 구글과 같은 대형 검색 포털의 문장 자동완성 기능, 스마트폰의 문자 자동완성 기능이 그것입니다. 이 기능에 사용된 인공지능 모델은 GPT의 머나먼 선배 격인 RNN(순환신경망)이지만, 학습 방식은 거의 같습니다.
우리가 이 문장 자동완성 기능을 처음 봤을 때, 크게 놀랐었나요? 그냥 ‘그렇구나~’ 정도로 넘기는 분위기였죠. GPT도 마찬가지입니다. GPT는 고도로 발달된 ‘문장 자동완성 기계’에 지나지 않습니다. 놀라지 않으셔도 돼요.
● ‘다음 낱말 맞추기 기계’는 ‘다음 문장 맞추기 기계’
‘나는 밥을’ 뒤에 ‘먹었다.’가 온다는 것을 맞추게 된 GPT. 또 뭘 할 수 있을까요? ‘나는 밥을 먹었다.’ 뒤에 어떤 단어가 올지도 맞출 수 있겠죠. 마찬가지로 그 자리에는 ‘말벌’ 같은 뜬금없는 단어보다는 ‘냉장고’나 ‘반찬’ 같은 명사가 나올 가능성이 크겠죠. 이런 식으로 ‘다음 단어 맞추기’를 반복해 단어를 하나씩 하나씩 맞춰서 붙이다보면 ‘나는 밥을 먹었다. 냉장고에서 반찬도 꺼내 먹었다.’처럼 문장 뒤에 새로운 문장을, 그 뒤에 또 다른 문장을 붙일 수 있게 됩니다. GPT는 이런 식으로 논문 한 편을 써내는 것이죠.
‘다음 단어 맞추기’를 반복해 논문 한 편을 쓰다니, 두서없는 글이 되기 십상일 것 같은데요. 실제로 검색어 자동 완성에 쓰였던 초기 버전 인공지능도 똑같이 여러 문장을 이어서 쓸 수 있었지만, 글이 길어지면 앞쪽에 썼던 내용을 까먹어 주제를 알 수 없는 글이 되어버리는 문제가 있었습니다. 그런데 모델을 개선할수록 앞에서 썼던 문장들의 정보를 유지해 주제를 일관되게 지킬 수 있는 길이가 점차 길어졌습니다. 마침내는 GPT 모델에 이르게 됐죠. 다만 챗GPT도 약 15번의 문답 이후에는 앞쪽의 정보를 잊어버리는 비슷한 문제를 안고 있습니다.
 대화형 인공지능 챗GPT는 한국이 기후변화에 대응하지 않을 경우 물부족과 폭염, 해수면 상승에 따른 피해를 받을 수 있다고 설명했다. 뉴스1
대화형 인공지능 챗GPT는 한국이 기후변화에 대응하지 않을 경우 물부족과 폭염, 해수면 상승에 따른 피해를 받을 수 있다고 설명했다. 뉴스1● ‘질문-답’ 대본을 학습한 ‘다음 문장 맞추기 기계’
또 다른 의문이 생깁니다. GPT가 단어에 단어를 이어 붙여 그럴듯한 글을 써내는 것까지는 이해한다고 칩시다. 그런 GPT는 어떻게 사람이 묻는 말에 답도 하게 됐을까요?
여기서 GPT의 두 번째 학습이 필요해집니다. 위키피디아를 잔뜩 학습시켰던 GPT에게 문장들을 생성하도록 하면, GPT는 위키피디아 문서의 형식을 닮은 글을 쓰게 됩니다. 유튜브 댓글을 잔뜩 학습한 GPT에게 문장들을 생성하도록 하면 유튜브 댓글 형식을 닮은 글을 쓰게 됩니다. 그러면 GPT에게 ‘질문-답’ 형식의 글을 잔뜩 학습시키면 어떨까요? GPT가 생성하는 글은 ‘질문-답’형식을 띄게 됩니다. 그러면 이 GPT에게 ‘질문’이 담긴 글을 주고, 글의 나머지 부분을 완성시켜보라고 하면 어떨까요? 네 맞습니다. GPT는 ‘답’을 작성하게 되겠죠.
이렇게 질문을 주면, 나머지 ‘답’ 부분을 완성시키도록 학습된 모델이 바로 챗GPT입니다.
챗GPT가 인간을 돕고 싶은 마음으로 가득 차서 사람들의 질문에 척척 답 해주는 것이 아닙니다. 챗GPT는 질문에 대한 상호작용으로써 대답을 하는 것도 아닙니다. 챗GPT는 단지 ‘나는 밥을’ 다음 단어를 찾아내듯, 반쯤 끊긴 글의 나머지 절반을 채우는 작업을 고독하게 수행하고 있을 뿐입니다.
예를 들어 GPT에게 ‘문: 꽃은 어디에 있나요? 답 : 화분에 있습니다’ 라는 글을 학습시켰다고 칩시다. GPT는 앞으로 이 글의 형식을 닮은 문장들을 만들어내게 되겠죠. 이 GPT에게 ‘문: 밥은 어디에 있나요?’라는 글을 주고, 뒷부분을 완성하도록 해봅시다. 그러면 GPT는 원본 글의 형식을 복원하려고 하면서, 앞에서 학습했던 ‘밥’과 ‘밥솥’의 관계를 적용해 ‘문: 밥은 어디에 있나요? 답 : 밥솥에 있습니다’ 라는 글을 완성하게 되는 것이죠. GPT가 앞서 학습한 여러 단어들 사이의 관계를 응용한다면, 이런 형식의 수많은 질문에는 적절히 답을 해줄 수 있겠네요.
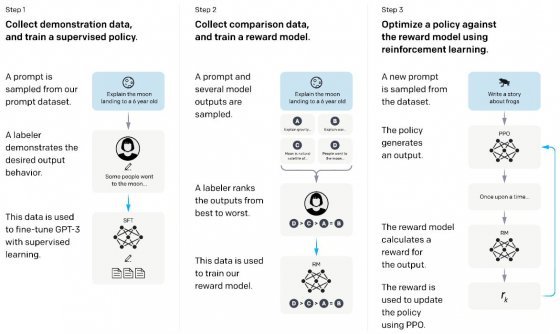 오픈AI의 챗GPT 논문에 실린 제작 과정. 수많은 직원들이 작성한 질문-답 대본을 챗GPT에 학습시켰다.
오픈AI의 챗GPT 논문에 실린 제작 과정. 수많은 직원들이 작성한 질문-답 대본을 챗GPT에 학습시켰다.● 40명의 알바가 써준 1만3000개의 컨닝 페이퍼
단지 여러 권의 책을 학습시켰더니 마법처럼 질문에 답을 척척 해내는 유연한 지성체가 탄생한 것이 아닙니다. 챗GPT에게 다양한 ‘질문-답’ 형식의 글을 잔뜩 학습시키기 위해 어마어마한 노력이 들어갔습니다. 챗GPT 제작사인 오픈AI는 40명의 계약직 인력을 고용해 GPT를 학습시킬 ‘질문-답’형식의 텍스트 1만3000개를 인간이 직접 작성하도록 했습니다.
이들에게 제공된 질문에는, 사람들이 챗GPT 초기 버전에 찾아와 입력했던 장난스러운 질문들도 모두 포함됐습니다. 직원들은 이 질문에 아주 길고 정성스러운 답을 직접 작성했습니다. 장차 챗GPT가 받게 될 웬만한 예상 질문들에 대한 모범답안 형식은 이미 인간의 손으로 다 작성이 됐다고 보면 되겠습니다. 거기에 ‘꽃’과 ‘화분’을 ‘밥’과 ‘밥솥’으로 바꾸는 종류의 변주가 가해지게 되는 것이죠.
직원들이 직접 작성한 ‘질문-답’ 대본에는, 챗GPT의 문답 중 세상을 깜짝 놀라게 했던 여러 가지 대화의 원본들이 있습니다. ‘개구리에 대한 소설을 써봐’라든지, ‘이 문장을 고쳐줘’라든지, ‘애기 이름을 지어줘봐. 예를들어 1.김병구 2.김민식’ 이라든지. 우리가 생각할 수 있는 웬만한 질문 유형들은 이미 직원들이 직접 그 틀이 되는 ‘질문-답’ 대본을 작성해놨습니다.
또 질문이 꼬리에 꼬리를 무는 경우에 대비해 직원들은 ‘질문-답-질문-답-질문-답’ 형식의 스크립트도 작성했습니다.
“인공지능이 어떻게 이런 질문에 답할 수 있지?” “어떻게 이렇게 반응할 수 있지?”라고 깜짝 놀랄만한 문답 대화의 기본적인 틀은 대부분 이미 직원들이 직접 손으로 써서 틀을 마련해놓은 것들이 많습니다. 그 원본이 챗GPT에 학습돼있는 것이죠.
챗GPT가 정말 성실하고 꼼꼼하게 답변한다고 느끼지 않으셨나요? 그것 또한 인간 직원들의 공이 상당히 큽니다. 오픈AI는 우선 이 40명의 계약직 직원을 채용할 때부터 상당한 노력을 기울였습니다. 오픈AI는 여러 명의 후보군 중에서 민감한 이슈를 적절히 판별하고 답하는 능력 등을 테스트해 40명을 선발했습니다. 이들에게 진실 되고 유용하며 성실한 대본을 쓰도록 적극적으로 교육했으며, 이들이 쓴 대본들은 공개 채팅 방에 공유됐기에 항상 감시와 검증을 받았습니다.
챗GPT는 이렇게 만들어진 꼼꼼한 질문-답 대본들을 응용해 다양한 질문에 대한 답을 만들고 있습니다. 때로 어떤 대답들은 비슷한 구조에 몇 가지 단어와 표현이 바뀐 것 같다는 느낌을 받게 되는 이유입니다. 또 미리 학습한 질문-답 형식을 벗어난 요청을 받으면 급격히 성능이 떨어지는 이유이기도 하죠. 챗GPT가 가끔 동문서답을 하는 이유를 이제 아시겠죠?
어떤가요. 이렇게 하나하나 떼어놓고 보니, 챗GPT는 단지 고도로 발달한 ‘빈칸 채우기 기계’에 지나지 않는다고 느껴지기도 합니다. 인간을 뛰어넘는 새로운 지성체가 나타났다는 두려움은 조금 가라앉는 듯 합니다.
 뉴스1
뉴스1● 맺으며:앎이란 무엇인가?
그런데 말입니다. 이번에는 인간의 ‘앎’이란 그러면 얼마나 대단한 것인가에 대해 한번 생각해볼 차례인 것 같습니다.
GPT가 ‘장미꽃’에 대한 지식을 습득하는 과정을 생각해봅시다. GPT는 수많은 글의 ‘다음 단어 맞추기’ 문제를 풀면서, ‘장미꽃’ 다음에는 ‘빨간색’, ‘사랑’, ‘가시’, ‘어린왕자’, ‘향기’ 등의 단어가 등장할 확률이 높다는 것을 학습하게 됩니다. GPT는 장미꽃이 뭔지도 모르고, 빨간색이 뭔지도 모르고, 사랑이나 가시, 어린왕자 등에 대해서도 전혀 모릅니다. 단지 이 단어들이 서로 연관이 있다는 것을 잘 알고 있을 뿐이죠.
그러면 반대로 사람들에게 물어보겠습니다. 여러분은 장미꽃이 무엇인지 알고 있나요? 자신이 장미꽃을 안다는 것을 어떻게 증명할 수 있나요? GPT는 할 수 없고, 인간만이 할 수 있는 방법으로 그것을 보여줄 수 있을까요.
어떤 사람은 이렇게 얘기할 수도 있습니다. “나는 백과사전 속 장미꽃의 정의를 외울 수 있다. 그러므로 나는 장미꽃을 ‘안다’고 할 수 있다”. 그러나 이것은 GPT도 할 수 있습니다. 어떤 사람은 장미꽃을 직접 봤던 경험을 떠올리며 이렇게 얘기할 것입니다. “나는 장미꽃을 알고 있지”. 사람은 자신이 경험한 것에 대해서는 ‘잘 알고 있다’라는 믿음을 갖는 경향이 있습니다. 특히 색감, 향기, 소리 등 감각에 대한 기억이 생생하게 떠오르면 그 믿음은 더 강해지겠죠. 물론 그 생생한 경험만큼은 GPT가 아직 따라할 수 없는 영역일 것입니다.
그런데 지금 컴퓨터 앞에 앉아있는 여러분에게 ‘장미꽃’에 대한 경험은 단지 지나간 과거의 일일 뿐입니다. 지금 여러분에게 남아있는 것은, 뇌 속에 흩어져있는 장미꽃에 대한 여러 가지 이미지와 키워드 조각들입니다. “그래서 장미꽃이 뭔데?”라고 묻는다면, 여러분은 “음…잎이 빨간 색이고, 향기가 나고, 뾰족뾰족한 가시가 돋아있는 꽃이야”라며 장미로부터 연상되는 단어들을 나열하는 수밖에 없겠죠. 결국 연관된 여러 가지 이미지와 키워드를 연상할 수 있다는 것이 우리의 앎의 증거입니다. 그렇다면 컴퓨터 앞에 앉아있는 여러분의 앎과 GPT의 앎은 얼마나 큰 차이가 있을까요. 그리고 앞으로 감각 센서로 실물을 경험할 수 있는 인공지능이 나타난다면, 우리는 그보다 얼마나 더 ‘안다’고 말할 수 있을까요.
서영빈 기자 suhcrates@donga.com





비즈N 탑기사












 김숙 “내 건물서 거주+월세 수입 생활이 로망”
김숙 “내 건물서 거주+월세 수입 생활이 로망” “20억 받으면서 봉사라고?”…홍명보 감독 발언에 누리꾼 ‘부글’
“20억 받으면서 봉사라고?”…홍명보 감독 발언에 누리꾼 ‘부글’ 세계적 유명 모델이 왜 삼성역·편의점에…“사랑해요 서울” 인증샷
세계적 유명 모델이 왜 삼성역·편의점에…“사랑해요 서울” 인증샷 “사람 치아 나왔다” 5000원짜리 고기 월병 먹던 中여성 ‘경악’
“사람 치아 나왔다” 5000원짜리 고기 월병 먹던 中여성 ‘경악’ “모자로 안가려지네”…박보영, 청순한 미모로 힐링 여행
“모자로 안가려지네”…박보영, 청순한 미모로 힐링 여행- 엄마 편의점 간 사이 ‘탕’…차에 둔 권총 만진 8살 사망
- 8시간 후 자수한 음주 뺑소니 가해자…한문철 “괘씸죄 적용해야”
- 교보생명, 광화문글판 가을편 새단장…윤동주 ‘자화상’
- 힐러리 “내가 못 깬 유리천장, 해리스가 깨뜨릴 것”
- ‘SNS 적극 활동’ 고현정…“너무 자주 올려 지겨우시실까봐 걱정”
 둔촌주공, 공사비 갈등에 도로-조경 등 스톱… 내달 입주 차질 우려
둔촌주공, 공사비 갈등에 도로-조경 등 스톱… 내달 입주 차질 우려 집값 꿈틀에 주택매매 늘자 9월 인구이동 3년만에 최대
집값 꿈틀에 주택매매 늘자 9월 인구이동 3년만에 최대 [단독]“한국이 폴란드산 자폭 드론 도입, 양국 방산협력의 상징”
[단독]“한국이 폴란드산 자폭 드론 도입, 양국 방산협력의 상징” “공예의 나라 정체성, K판타지아 프로젝트로 되살릴 것”
“공예의 나라 정체성, K판타지아 프로젝트로 되살릴 것” 9월 인구이동 ‘46만명’ 3.1%↑…“주택 매매량 증가 영향”
9월 인구이동 ‘46만명’ 3.1%↑…“주택 매매량 증가 영향”- 기업 10곳 중 8곳 “정년 연장 긍정적”…평균 65.7세
- 청력 손실, 치매 외 파킨슨병과도 밀접…보청기 착용하면 위험 ‘뚝’
- “두바이 여행한다면 체크”…두바이 피트니스 챌린지
- 배달료 올리자 맘스터치 버거값 인상… “결국 소비자만 고통”
- “20억 받으면서 봉사라고?”…홍명보 감독 발언에 누리꾼 ‘부글’